Nacionalna infrastruktura odprtega dostopa - dostop
do znanja slovenskih raziskovalnih organizacij
Slovenske univerze so leta 2013 s sofinanciranjem
Evropskega sklada za regionalni razvoj in Ministrstva za izobraževanje, znanost
in šport vzpostavile nacionalni portal odprte znanosti ter repozitorije za
odprti dostop do zaključnih del študija in rezultatov raziskav raziskovalcev.
Uporabnikom z vsega sveta so na voljo dvojezični spletni in mobilni vmesniki in
priporočilni sistem. To infrastrukturo smo v letih od 2014 do 2022 dopolnili z
repozitorijema za samostojne raziskovalne organizacije in ostale višješolske in
visokošolske inštitucije, nacionalnim strežnikom za dodeljevanje trajnih
identifikatorjev in arhivom za velepodatke. Vključili pa smo tudi več drugih
ponudnikov rezultatov njihovih raziskav. Z vzpostavitvijo repozitorijev in
nacionalnega portala odprte znanosti je raziskovalcem, študentom, podjetjem in ostalim
uporabnikom doma ter po svetu omogočen dostop do raziskovalnih rezultatov
slovenskih raziskovalnih organizacij. Raziskovalci imajo na voljo
infrastrukturo, ki jim omogoča izpolnjevanje določil o obvezni odprti
dostopnosti rezultatov raziskav iz javno financiranih raziskav.
Podrobnejši opis vzpostavitve nacionalne
infrastrukture odprtega dostopa v letu 2013 najdete v članku: Milan Ojsteršek,
Janez Brezovnik, Mojca Kotar, Marko Ferme, Goran Hrovat, Albin Bregant, Mladen
Borovič, (2014) "Establishing of a Slovenian
open access infrastructure: a technical point of view", Program:
electronic library and information systems, letnik 48 številka: 4, str. 394
– 412.
Nacionalni portal in ostali podsistemi
nacionalne infrastrukture odprtega dostopa
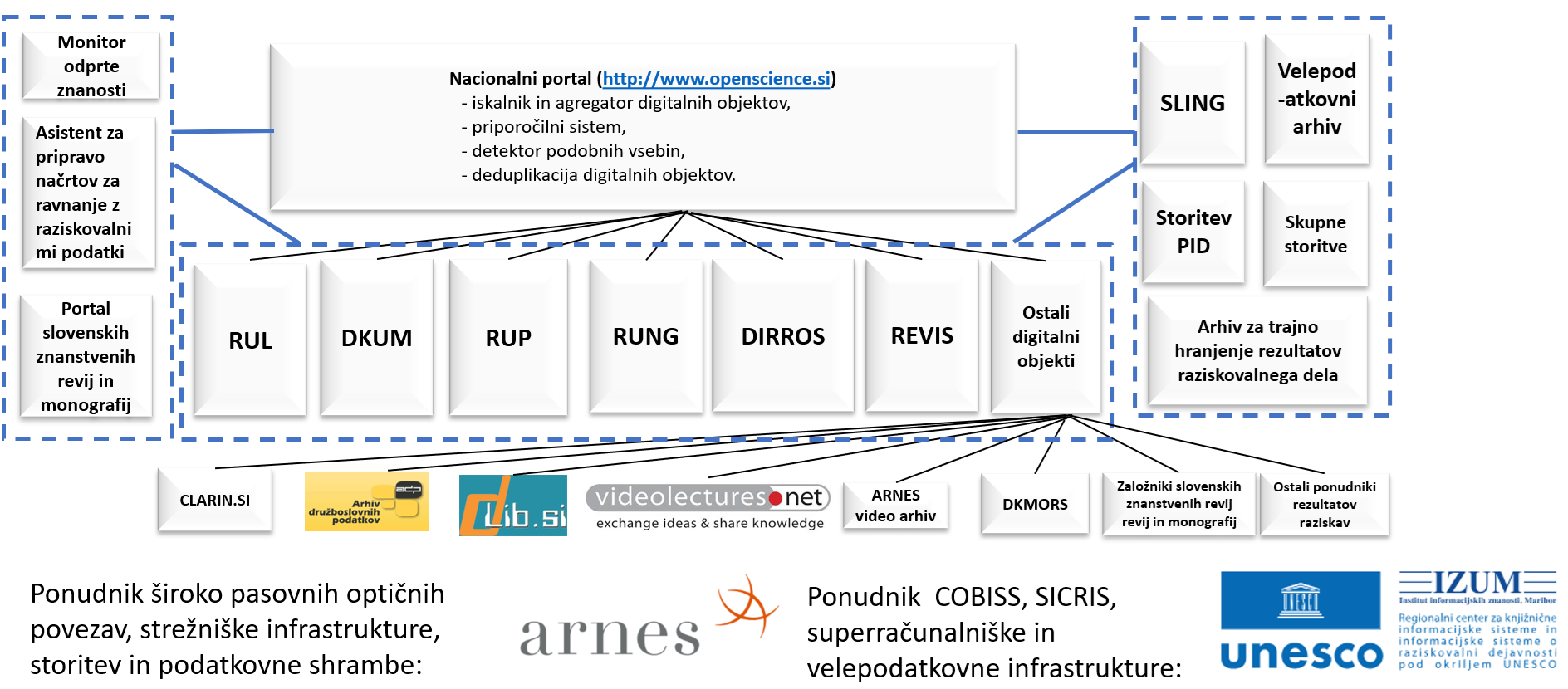
Slika
1: Strukturni diagram nacionalne infrastrukture odprte znanosti
Nacionalno infrastrukturo odprtega dostopa sestavlja šest repozitorijev in nacionalni portal, ki agregira metapodatke, drugi repozitoriji ter drugi ponudniki digitalnih objektov (Digitalna knjižnica Slovenije - dLib, CLARIN, Arhiv družboslovnih podatkov - ADP, Digitalna knjižnica Ministrstva za obrambo - DKMORS, CLARIN.si, Videolectures.NET, revije in monografije založb iz SAZU, slovenskih univerz in drugih založnikov, idr.). Kompatibilnost repozitorijev z navodili OpenAIRE Evropski komisiji omogoča preverjanje izpolnjevanja določil o obvezni odprti dostopnosti vseh objav iz sofinanciranih projektov. Repozitoriji univerz so povezani s COBISS.SI in SICRIS-om, vključeni v evropski portal magistrskih ter doktorskih del DART-Europe in v različne spletne imenike, agregatorje ter iskalnike (OpenDOAR, ROAR, BASE …). Vzpostavljena infrastruktura Sloveniji omogoča izvajanje politike odprtega dostopa do rezultatov nacionalno financiranih raziskav, kot se pričakuje od držav članic EU, ki sodelujejo v ERA. Nacionalni portal openscience.si agregira vsebine iz slovenskih repozitorijev in drugih slovenskih zbirk za potrebe združevalnega iskalnika, priporočilnega sistema in preverjanja podobnosti vsebin. Repozitorij dCOBISS na podlagi agregiranih podatkov o odprtih objavah v repozitorijih omogoča financerjem preverjanje skladnosti pogodbenih obveznosti z dejansko odprtostjo znanstvenih objav, omogočil pa bo tudi različne statistične podatke o odprtih znanstvenih objavah (npr. število in vsota plačanih stroškov procesiranja člankov (ang. Article Processing Charge – APC), podatke o platformah odprtih objav, podatke o založnikih, podatke o uporabljenih licencah in drugo). V okviru nacionalne infrastrukture odprtega dostopa je vzpostavljena storitev za dodeljevanje trajnih identifikatorjev digitalnih objektov ter arhiv za hranjenje velepodatkov. Infrastruktura je povezana s slovenskim nacionalnim superračunalniškim omrežjem SLING, nacionalnim Covid19 portalom in Evropskim Covid19 portalom. Akademsko računalniško omrežje ARNES nam omogoča uporabo hrbteničnega omrežja, ki temelji na široko pasovnih optičnih povezavah. Na svoji strežniški infrastrukturi gostijo tudi repozitorija DIRROS in REVIS. Njihovo diskovno shrambo uporabljamo za shranjevanje varnostnih kopij. Inštitut informacijskih znanosti Maribor pa nam omogoča uporabo superračunalnika VEGA in velepodatkovnega arhiva, iz katerega lahko uporabniki obdelujejo podatke na Slovenskem nacionalnem superračunalniškem omrežju (SLING) ter na drugih superračunalnikih po Evropi. IZUM vzdržuje nacionalni bibliografski katalog COBISS in nacionalni sistem za vrednotenje raziskovalnega dela SICRIS. Infrastruktura omogoča Sloveniji izvajanje politike odprtega dostopa do rezultatov nacionalno financiranih raziskav, kar se pričakuje od držav članic EU, ki sodelujejo v ERA.
Slovenija je na področju odprte znanosti sprejela Akcijski načrt za odprto znanost (https://www.aris-rs.si/sl/dostop/inc/24/Akcijski_nacrt_odprta%20znanost.pdf), ki definira aktivnosti, s pomočjo katerih bo Slovenija izboljšala kvaliteto raziskovalnega dela, njegovo učinkovitost in odzivnost. Akcijski načrt za odprto znanost definira aktivnosti, ki so vezane na vzpostavitev ustrezne zakonodaje, procesov, zaposlitev in izobraževanje podatkovnih strokovnjakov, izobraževanje raziskovalcev, vzpostavitev novih storitev in infrastrukture. Aktivnosti iz Akcijskega načrta omogočajo prilagoditev nacionalnega ekosistema odprte znanosti, da bo harmoniziran z aktivnostmi v EOSC. Delamo na izboljšanju infrastrukture, storitev, podatkovnih prostorov, podpore uporabnikom, zakonodaje in procesov na državnem in institucionalnem nivoju. Vzpostavljamo podporno strukturo podatkovnih svetovalcev, ki pomagajo in svetujejo raziskovalcem pri izvedbi njihovih raziskav po načelih FAIR. Pri implementaciji nacionalnega vozlišča EOSC, ki ga koordinira ARNES, sodelujejo vsi ključni akterji na področju odprte znanosti v Sloveniji in so locirani po celi Sloveniji.
Spletne povezave:
Najpomembnejše prednosti slovenske infrastrukture pred drugimi nacionalnimi infrastrukturami so:
- Nacionalni pristop k izgradnji nacionalne infrastrukture odprte znanosti in digitalnih objektov FAIR.
- Nacionalna storitev PID.
- Nacionalni arhiv velikih podatkov.
- Za vse vključene inštitucije so pripravljene predloge politik o obveznem izvodu raziskovalnih publikacij, raziskovalnih podatkov, zaključnih del in drugih rezultatov raziskav (programska oprema, delovni postopki, laboratorijski zvezki, e-učna gradiva ...).
- Stalni razvoj in dopolnitve procesov za deponiranje publikacij, zbirk raziskovalnih podatkov in drugih raziskovalnih rezultatov študentov in raziskovalcev v vseh vključenih inštitucijah.
- Repozitoriji univerz uporabljajo lastno programsko opremo, ki je integrirana z informacijskimi in avtentikacijskimi sistemi univerz, nacionalnim bibliografskim sistemom COBISS.SI, nacionalnim sistemom za vodenje evidence raziskovalnega dela SICRIS in nacionalnim portalom openscience.si.
- Detektor podobnih vsebin je vključen v proces oddaje zaključnih del študija in v oddajo del raziskovalcev.
- Priporočilni sistem omogoča priporočanje gradiv znotraj posameznega repozitorija in med repozitoriji ter zunanjimi sistemi (VideoLectures.NET, DKMORS in dLib.si).
- Aplikacijski programski vmesnik, ki omogoča uporabo različnih funkcionalnosti repozitorijev.
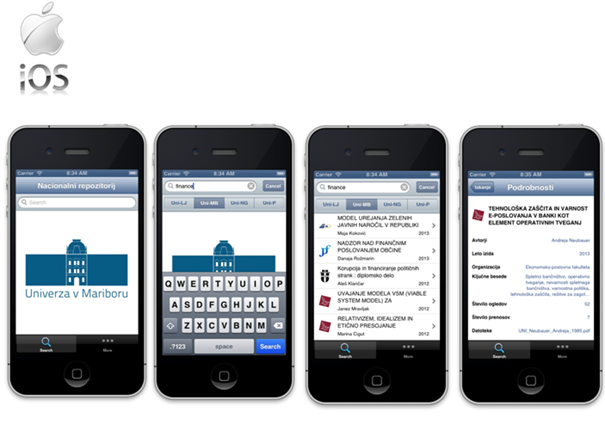
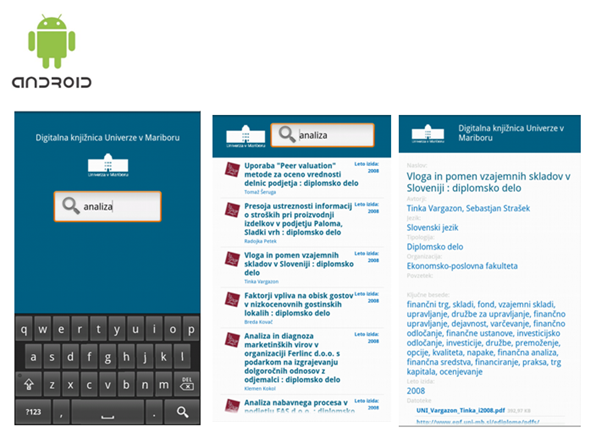
- Mobilne aplikacije za Android in IOS ter vmesnik HTML5 omogočajo dostop do repozitorijev z mobilnih telefonov in drugih prenosnih naprav.
- Nacionalna infrastruktura odprtega dostopa je povezana s slovenskim bibliografskim sistemom COBISS.SI. Nacionalni portal in institucionalni repozitoriji izvajajo izmenjavo metapodatkov s COBISS.SI preko Aplikacijsko programskega vmesnika prek vmesne baze Metadat.
- Integracija z nacionalnim informacijskim sistemom za tekoče raziskave SICRIS, ARNES AAI, Crossref, Datacite.
- Analitika odprodostopnih publikacij in drugih rezultatov raziskav se izvaja preko aplikacijskega programskega vmesnika v dCOBISS.
Repozitoriji
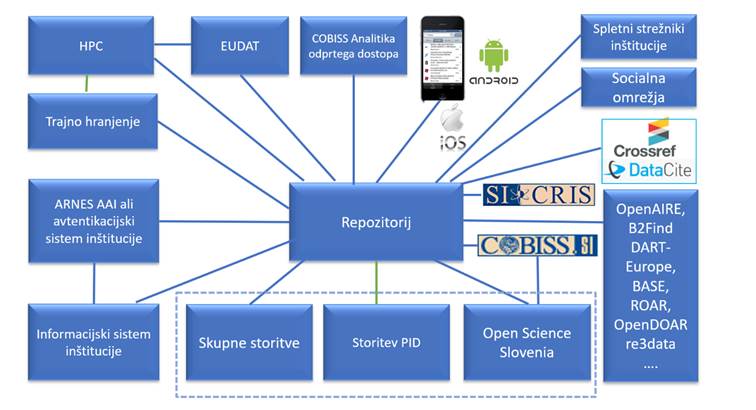
Slika 2: Struktura repozitorijev nacionalne
infrastrukture odprtega dostopa
Programska oprema za repozitorije (slika 2)
temelji na programski rešitvi, ki jo uporablja Digitalna knjižnica Univerze v
Mariboru in jo je razvil Laboratorij za heterogene računalniške sisteme Univerze
v Mariboru. Zaradi vzpostavitve različnih procesov oddaje publikacij s strani
študentov in zaposlenih na univerzah je bila bistveno dopolnjena ter nadgrajena
z novimi funkcionalnostmi.
Za potrebe procesov oddaje, hranjenja in
katalogizacije digitalnih objektov je vsak institucionalni repozitorij univerz
v Mariboru, Ljubljani, na Primorskem in v Novi Gorici povezan z
avtentikacijskim sistemom univerze, univerzitetnim visokošolskim informacijskim
sistemom in sistemom COBISS.SI. Tudi v repozitoriju REVIS je kar nekaj
inštitucij, ki imajo povezan svoj akademski informacijski sistem z repozitorijsko
programsko opremo.
Vsak digitalni objekt dobi nacionalni trajni
identifikator (PID) tako da po njegovi katalogizaciji repozitorijska programska
oprema kliče nacionalno storitev, ki vrača trajne identifikatorje. Za
dodeljevanje trajnih identifikatorjev uporabljamo EUDATovo storitev B2Handle.
Velepodatke hranijo repozitoriji v arhivu za
velepodatke. Za njihovo arhiviranje uporabljamo EUDATovo storitev B2Safe. Za
prenos podatkov med superračunalniki in arhivi velepodatkov uporabljamo
EUDATovo storitev B2Stage.
Za pohitritev vpisa metapodatkov digitalnih
objektov, ki že imajo dodeljen trajni identifikator DOI uporabljamo storitve,
ki jih ponujata Crossref in Datacite. Repozitorijska programska oprema kliče
storitev tako, da kot vhod v storitev pošlje trajni identifikator DOI, nazaj pa
pridobi metapodatke, ki jih hranita o tem digitalnem objektu Crossref in
Datacite.
Za potrebe agregiranja metapodatkov s strani
OpenAire imamo vzpostavljen storitev OAI-PMH, ki vrača metapodatke po
navodilih, ki jih je podal OpenAire. Preko te storitve agregirajo metapodatke
tudi drugi agregatorji ( Core, Dart Europe, Base…). Za Google Scholar in Google
Dataset search smo vgradili v spletno stran za posamezne digitalne objekte
metapodatke po formatu Highwire press in po specifikaciji Schema.org.
Na Univerzi v Ljubljani se po shranitvi v njihov
repozitorij digitalni objekti shranijo še v dokumentni sistem Univerze. Za arhiviranje
digitalnih objektov in njihovih metapodatkov se uporablja nacionalni portal in
infrastruktura, ki je vzpostavljena na ARNESu in IZUMu.
Repozitoriji pošiljajo v nacionalni portal
metapodatke in elektronske verzije digitalnih objektov takoj po izvedeni
katalogizaciji v COBISS.SI. Iz nacionalnega portala pa repozitorij Univerze v
Ljubljani pridobiva metapodatke in elektronske verzije publikacij iz
ePrints.FRI, PeFprints in ADP. Prav tako repozitorij iz nacionalnega portala
pridobi dodatne podatke o raziskovalcih in raziskovalnih organizacijah, ki jih
slednji črpa iz SICRIS-a.
Repozitoriji pošiljajo v dCOBISS podatke, ki
so potrebni za analitiko odprtega dostopa. Podatki, ki jih pošiljajo so vezani
na projekte iz katerih je bila financirana raziskava in na plačila APC-jev, ki
jih zaračunajo založniki.
Nacionalni portal izvaja priporočanje gradiv.
Ob kliku na dokument v repozitoriju se iz nacionalnega portala pošlje v
institucionalni repozitorij seznam podobnih dokumentov. Priporočilo je
sestavljeno iz naslovov dokumentov znotraj repozitorija in naslovov dokumentov
v drugih univerzitetnih repozitorijih, dLib.si, Arhiva družboslovnih podatkov
CLARIN.si, repozitorijev založnikov revij in monografij, VideoLectures.NET in
DKMORS.
Repozitoriji omogočajo funkcionalnosti, ki so
namenjene skrbnikom, in funkcionalnosti, ki so namenjene uporabnikom. Skrbniški
del uporabljajo referenti v študijskih referatih, knjižničarji podatkovni
svetovalci in skrbniki sistema in je različno zasnovan za posamezne inštitucije.
Referenti izvajajo pregled in zaklepanje zaključnih del študentov. Knjižničarji
pregledujejo publikacije študentov in zaposlenih, jih katalogizirajo v COBISS-u
ter njihove metapodatke iz COBISS.SI prenesejo v repozitorij. V skrbniškem delu
lahko knjižničar metapodatke o publikaciji uvozi iz lokalne baze COBISS.SI in
jim doda elektronsko različico publikacije. Na tak način je mogoče v
repozitorij shraniti tudi publikacije, ki so že katalogizirane v COBISS.SI in
zanje obstajajo elektronske različice ter ima univerza zanje ustrezno urejene
avtorske pravice.
Uporabniški del institucionalnega
repozitorija je razdeljen na del, ki je namenjen zainteresirani javnosti, in
del, ki je namenjen prijavljenim uporabnikom (študentom in zaposlenim na
univerzah; različna zasnova za posamezne univerze). Študenti in zaposleni na univerzah
lahko po prijavi oddajo svoja dela v repozitorij ter pregledujejo svoje vsebine
(metapodatke in podobna dela, ki jih je našel detektor podobnih vsebin). Del,
ki je dostopen zainteresirani javnosti, je dvojezičen (slovenski in angleški
uporabniški vmesnik) ter je dostopen preko spleta in na mobilnih platformah
(Android in IOS). Spletna različica je prijazna do uporabnikov s posebnimi
potrebami in vsebuje glavne značilnosti spletnih aplikacij, ki ustrezajo
specifikaciji WAI. Spletni vmesnik omogoča uporabo invalidom z zmanjšano
gibalno sposobnostjo in osebam, ki vidijo nekoliko slabše (npr. starejši in
slabovidni).
Programska oprema omogoča enostavno in
napredno iskanje ter brskanje. Članica univerze lahko prikaz vključi na svojo
spletno stran tako, da kliče ustrezen JavaScript program ali uporabi JavaScript
API za dostop do enostavnega ali naprednega iskanja ter brskanja po
institucionalnem repozitoriju. Enak API uporabljajo tudi mobilne aplikacije.
Članicam univerz in zaposlenim na univerzah je omogočen tudi izvoz metapodatkov
o njihovih publikacijah v obliki RSS, JSON in RDF.
Repozitorij prikazuje različne statistike, s
pomočjo katerih lahko za vsako inštitucijo ali posamezno enoto znotraj
inštitucije ugotovimo celotno število njenih digitalnih objektov v repozitoriju
in koliko jih je bilo shranjenih v zadnjem obdobju ter število vpogledov v metapodatke
in ali prenosov digitalnega objekta. Za fakultete posamezne univerze so
zanimive statistike, ki poročajo o številu ogledov in prenosov gradiv fakultete
za pretekla leta na letni ravni. Iz statistik mentorjev zaključnih del študija
lahko ugotovimo, s katerimi somentorji slednji sodelujejo in katera zaključna
dela študija so študenti izdelali pod njihovim mentorstvom. Zanimiva je tudi
statistika, ki na podlagi ključnih besed publikacij mentorja posredno prikaže,
s katerimi raziskovalnimi področji se slednji ukvarja in kako se je skozi
časovno obdobje spreminjalo njegovo raziskovalno področje.
Storitve nacionalnega portala
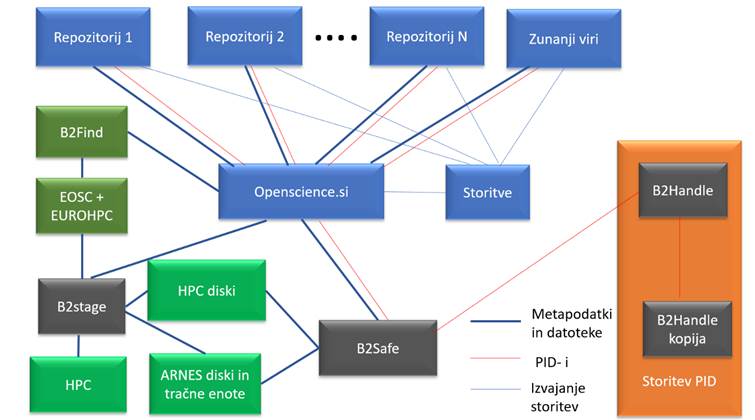
Slika 3. Struktura sistema
skupnih storitev nacionalnega portala
Repozitoriji uporabljajo skupne storitve, ki jih ponuja nacionalni portal (slika 3). Te storitve so:
- Storitev za dodeljevanje trajnega identifikatorja (PID): Vsak digitalni objekt dobi nacionalni trajni identifikator (PID) tako da po njegovi katalogizaciji repozitorijska programska oprema kliče nacionalno storitev, ki vrača trajne identifikatorje. Za dodeljevanje trajnih identifikatorjev uporabljamo EUDATovo storitev B2Handle.
- Velepodatkovni arhiv: Velepodatke hranijo repozitoriji v arhivu za velepodatke. Za njihovo arhiviranje uporabljamo EUDATovo storitev B2Safe. Za prenos podatkov med superračunalniki in arhivi velepodatkov uporabljamo EUDATovo storitev B2Stage
- Skupne storitve:
- Storitev priporočilnega sistema. Storitev vrača za vsak digitalni objekt najbolj podobne digitalne objekte v istem repozitoriju in digitalne objekte iz drugi repozitorijev in zunanjih repozitorijev in arhivov, ki so vključeni v nacionalno infrastrukturo odprtega dostopa.
- Storitev pretvorbe različnih vrst dokumentov v besedilo.
- Storitev optične razpoznave slik in pretvorbo besedila iz slik v tekst.
- Storitev detekcije podobnih vsebin. Storitev za vsak digitalni objekt, ki vsebuje datoteke, iz katerih se da pridobiti tekst, poišče najbolj podobna besedila.
- Storitev za določanje geografskega in časovnega pokritja. Storitev omogoča določitev geografskega in časovnega pokritja, ki ga preko spletne aplikacije določi uporabnik repozitorija. Metapodatki o geografskem in časovnem pokritju se dodajo med metapodatke določenega digitalnega objekta. Storitev je še v testni fazi.
Proces oddaje zaključnih del študentov na
Univerzah v Mariboru in v Novi Gorici
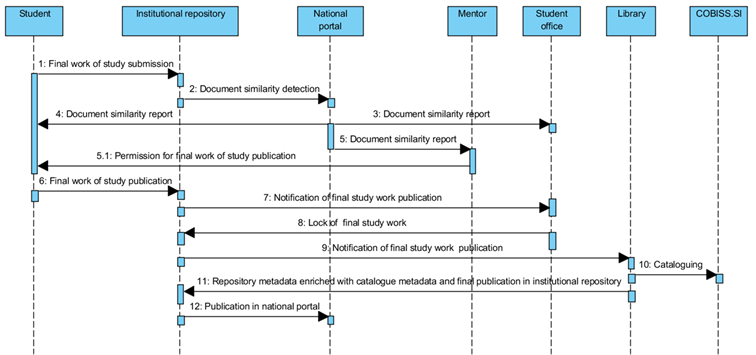
Slika 4: Sekvenčni diagram
procesa oddaje zaključnih del študentov na Univerzah v Mariboru in v Novi
Gorici
Študenti univerz v Mariboru in
Novi Gorici zaključno delo študija oddajo na vmesniku repozitorija (slika 4),
študenti univerz v Ljubljani in na Primorskem pa v študijski informatiki
članice oziroma univerze ( slika 5).
Ko študent odda zaključno delo
v institucionalni repozitorij Univerze v Mariboru ali univerze v Novi Gorici,
institucionalni repozitorij pokliče storitev, ki za vse oddane dokumente
preveri podobnost z drugimi deli. Storitev vrne povezavo na spletno stran, kjer
lahko mentor, študent ali uslužbenec referata preverijo v kolikšni meri je delo
podobno z drugimi. Prav tako si lahko iztiskajo poročilo o podobnosti z drugimi
deli.
Ko je mentor na univerzi v
Mariboru ali v Novi Gorici zadovoljen s končno različico zaključnega dela,
lahko študent zaključi oddajo elektronske oblike zaključnega dela v
institucionalni repozitorij, tiskano različico pa odda v študijski referat.
Slednji preveri istovetnost
tiskane in elektronske različice zaključnega dela ter izjave, ki sta jih
podpisala študent in mentor. To so izjave o vsebinski in oblikovni ustreznosti,
istovetnosti tiskane ter elektronske verzije dela, o neizključnem prenosu
materialnih avtorskih pravic in o določitvi embarga za prikaz dela na svetovnem
spletu.
Po zagovoru zaključnega dela,
knjižničar dobi tiskano različico publikacije in delo katalogizira v COBISS.SI.
Postopek oddaje s slikami je
prikazan na https://dk.um.si/info/index.php/slo/oddaja-dela oz. na
priponki https://dk.um.si/info/images/docs/postopek.oddaje.zakljucnega.dela.dkum.150722.pdf
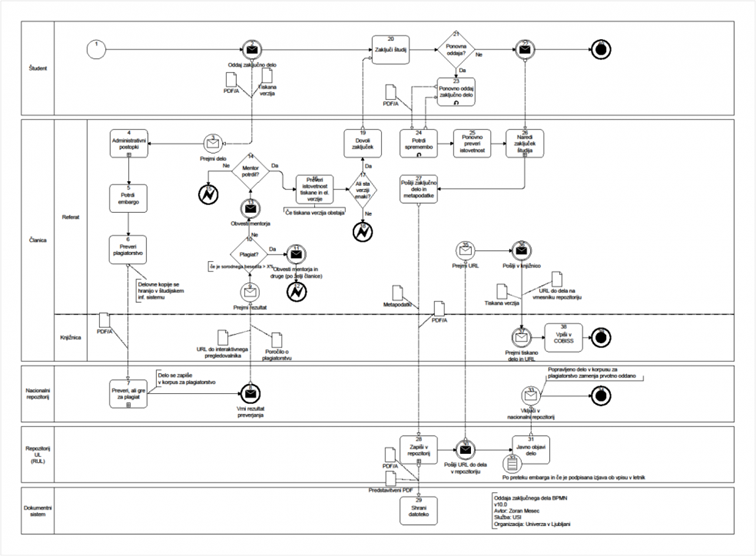
Slika 5: Procesni diagram
oddaje zaključnega dela na Univerzi v Ljubljani in na Univerzi na Primorskem
Proces oddaje publikacije raziskovalca
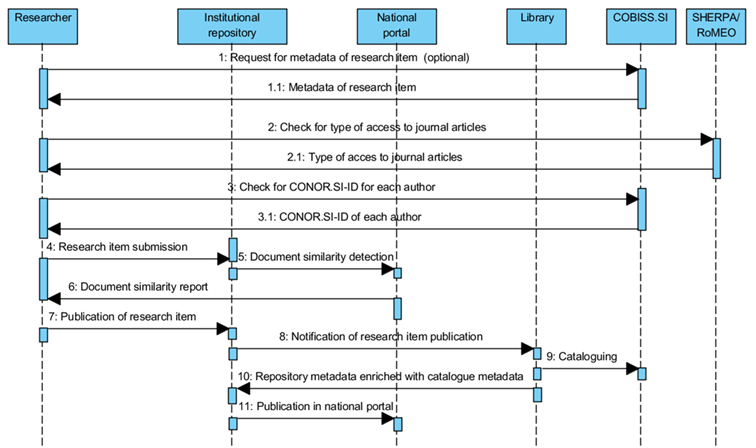
Slika 6: Sekvenčni diagram
procesa oddaje publikacije raziskovalca
Na vseh štirih univerzah smo za
potrebe shranjevanja publikacij raziskovalcev vzpostavili enak proces (slika 6).
Raziskovalec lahko v institucionalni repozitorij shranjuje članke, poglavja ali
sestavke v monografiji, prispevke na konferenci, monografije, visokošolske
učbenike ali druga učna gradiva, patente, raziskovalne podatke in druge vrste
publikacij. Vrste publikacij smo prilagodili tipologiji dokumentov za vodenje
bibliografij v sistemu COBISS.SI. Del metapodatkov je različen za različne
vrste publikacij. Raziskovalec se prijavi v institucionalni repozitorij, vpiše
metapodatke in odda elektronsko različico gradiva ali uporabi metapodatke o
katalogiziranem gradivu iz COBISS.SI.
Programska oprema
institucionalnega repozitorija omogoča avtorjem gradiv tudi povezavo s portalom
SHERPA/RoMEO, da lahko preverijo kakšno vrsto dostopa do elektronske različice članka
v reviji lahko uporabijo glede na pogodbo o prenosu avtorskih pravic, ki so jo
sklenili z založnikom. Prav tako vnašalcu metapodatkov ob vnosu imen in
priimkov avtorjev programska oprema ponudi predloge avtorjev v bazi CONOR.SI.
Avtor lahko za svoja dela vpiše nosilca avtorskih pravic in vrsto dostopa do
celotnega besedila (takojšnja dostopnost na svetovnem spletu, odlog objave do
poteka datuma embarga ali zaprt dostop) ter vpiše datum embarga. Zadnji
navedeni metapodatki so del kompatibilnosti z navodili OpenAIRE, ki omogočajo,
da strežnik OAI-PMH v institucionalnih repozitorijih vrača OpenAIRE
kompatibilen XML, tako da lahko strežniki portala OpenAIRE zajemajo metapodatke
o slovenskih publikacijah, ki so bile financirane s sredstvi EU ali drugih javnih
financerjev.
Priporočilni sistem
Slika 7: Prikaz priporočenih
gradiv
Sistemi priporočanja so
uveljavljeni predvsem na spletnih straneh, ki se ukvarjajo s prodajo izdelkov
ali reklam. Vedno bolj se uveljavljajo tudi v institucionalnih repozitorijih. Glavni
cilj teh sistemov je uporabnikom ponuditi vsebine, ki bi jih zanimale.
Obstaja več pristopov k
priporočanju, ki jih delimo v dve skupini. Prvo skupino predstavljajo pristopi,
ki delujejo izključno nad uporabniškimi aktivnostmi (Su in Khoshgoftaar, 2009).
Raziskovalci, ki razvijajo algoritme, katerih vhod so uporabniške aktivnosti,
analizirajo verjetnost, da bo uporabnik izbral neko vsebino, če so jo izbrali
tudi drugi uporabniki, ki jih zanimajo podobne stvari. Najbolj razširjeni
algoritmi so vezani na sodelovalno filtriranje (angl. collaborative filtering),
pristope z binarnimi vektorji in algoritem SlopeOne. Druga skupina pristopov
priporočanja deluje zgolj nad vsebino, uporabniške aktivnosti so postranskega
pomena in se lahko uporabljajo za dodatne uteži pri razvrščanju rezultatov.
Primeri algoritmov za priporočanje sorodnih vsebin so BM25, k najbližjih
sosedov, latentna pomenska analiza (LSA) in drugi, ki so bili izpeljani iz
podobnih predpostavk. Poleg tega se pristopi razlikujejo tudi glede na to, ali
se priporočanje izvaja v realnem času (angl. memory based recommendation) ali
pa so rezultati vnaprej pripravljeni in se enkrat ali večkrat dnevno na novo
izračunajo (angl. model based recommendation) ali pa je uporabljen hibridni
pristop (Bobadilla et al., 2013).
Priporočilni sistem v
institucionalnih repozitorijih omogoča, da ima uporabnik ob prikazu
metapodatkov izbranega dokumenta na voljo tudi informacije o dokumentih, ki so
po vsebini podobni izbranemu dokumentu, pri čemer izločimo vse dokumente, ki so
delni duplikati izbranega dokumenta. Delne duplikate določimo tako, da
uporabimo rezultate primerjave podobnih povedi in znakovne primerjave, ki smo
ju opisali v prejšnjem poglavju.
V programski opremi smo
uporabili vsebinsko priporočanje dokumentov, ki deluje po algoritmu izračuna
vrednosti BM25 in uporablja še dodatne uteži (Borovič, 2012), ki so pridobljene
iz metapodatkov dokumentov in opazovanjem uporabnikovih aktivnosti. Algoritem
deluje na naslednji način: najprej za vsako publikacijo nad metapodatki
(avtorji, naslov, ključne besede, povzetek) in celotnim besedilom izvedemo
lematizacijo ter pomensko označevanje besednih zvez, s pomočjo člankov iz
Wikipedije in ključnih besed, ki smo jih dobili iz metapodatkov vseh publikacij
v nacionalnem portalu (Burjek, 2011). Za te besedne zveze izračunamo njihovo
število pojavitev v vseh dokumentih (TF) in inverzno frekvenco IDF, ki je
vezana na pojavitev te besede v posameznem dokumentu. Večjo utež IDF damo
besednim zvezam iz metapodatkov o publikaciji (avtorji, naslov, ključne besede
in povzetek). Nato izračunamo podobnost z ostalimi dokumenti po formuli, ki so
jo predlagali Robertson, Zaragoza in Taylor (Robertson et al., 2004). V
izračunani matriki se nato izločijo tisti pari, ki imajo izračunano vrednost 0,
saj to pomeni, da takšna dokumenta nimata skupnih lastnosti. Tako ostane le še
seznam podobnosti, ki ga shranimo v podatkovno bazo. Postopek shranjevanja v
podatkovno bazo je namenjen temu, da lahko ob zahtevi za priporočanje zelo
hitro vrnemo ustrezne dokumente. Prag priporočanja dokumentov nastavimo glede
na razliko vrednosti BM25 našega dokumenta z vrednostmi BM25 drugih dokumentov.
Priporočanje sorodnih dokumentov je torej rezultat izbiranja N dovolj podobnih
dokumentov iz seznama vrednosti BM25. Seznam priporočenih dokumentov je lahko
tudi prazen, če priporočilni sistem ne najde podobnih dokumentov.
Vsebinsko priporočanje se v
nacionalni infrastrukturi odprtega dostopa izvaja na nacionalnem portalu. Ob
kliku na dokument v institucionalnem repozitoriju se z nacionalnega portala v
institucionalni repozitorij pošlje seznam podobnih dokumentov. Priporočilo je
sestavljeno iz naslovov dokumentov znotraj institucionalnega repozitorija in
naslovov dokumentov v drugih digitalnih zbirkah (dLib.si, VideoLectures.NET in
DKMORS).
Viri
Bobadilla, J., Ortega, F.,
Hernando, A. in Gutiérrez, A. (2013). Recommender systems survey.
Knowledge-based systems, 46 (7), 109-132. Pridobljeno 4. 6. 2014 s
spletne strani: http://dx.doi.org/10.1016/j.knosys.2013.03.012.
Borovič, M. (2012). Sistem
priporočanja dokumentov in analiza kvalitete vsebinskega priporočanja pri
različnih obdelavah vhodnega besedila. Magistrsko delo. Maribor: Fakulteta za
elektrotehniko, računalništvo in informatiko. Pridobljeno 4. 6. 2014 s spletne
strani: http://dkum.uni-mb.si/IzpisGradiva.php?id=37811.
Burjek, M. (2011). Wikifikacija
vsebin v digitalni knjižnici UM. Diplomsko delo. Maribor: Fakulteta za
elektrotehniko, računalništvo in informatiko. Pridobljeno 4. 6. 2014 s spletne
strani: http://dkum.uni-mb.si/IzpisGradiva.php?id=20570.
Robertson, S., Zaragoza, H. in
Taylor, M. (2004). Simple BM25 extension to multiple weighted fields. V
Proceedings of the thirteenth ACM international conference on Information and
knowledge management. New York: ACM, 42–49.
Su, X. in Khoshgoftaar, T. M.
(2009). A survey of collaborative filtering techniques. Advances in
artificial intelligence, Article ID 421425, 19 strani. Pridobljeno 4. 6.
2014 s spletne strani: http://dx.doi.org/10.1155/2009/421425.
Detektor podobnih vsebin
Za potrebe detekcije podobnih
vsebin v sistemu za upravljanje z učnimi vsebinami smo razvili vtičnik, ki ga
uporabljajo na Univerzi v Mariboru, Univerzi na Primorskem, v ARNESovih
učilnicah, Policijski akademiji, in na več samostojnih visokošolskih zavodih.
V vtičniku je možno konfigurirati katere dokumente bo Moodle pošiljal v
detekcijo podobnosti. V ARNESovih učilncah je možno definirati ali bo določena
spletna učilnica uporabljala detekcijo podobnih vsebin ter ali se detekcija
izvede takoj ob vstavljanju dokumenta v Moodle, ali pa se izvede, ko poteče rok
oddaje naloge.
Sistem za ugotavljanje podobnosti
med dokumenti je zasnovan tako, da lahko procent podobnosti vstavljenih del
preverijo samo njihovi avtorji ali pedagoški delavci, ki so definirali določeno
nalogo. Za univerze in fakultete smo pripravili tudi skrbniški vmesnik, preko
katerega lahko avtorizirani uporabniki pregledujejo podobnost vseh del določene
fakultete ali univerze. Te uporabnike določi vodstvo fakultete ali univerze in
lahko tudi vstavljajo dela v skrbniškem vmesniku ali določajo spletne vire, ki
bi jih želele fakultete ali univerze vključiti v preverjanje podobnosti s
svojimi dokumenti. Možen je tudi dostop do skrbniškega vmesnika ob uporabi
avtentikacije Arnes AAI. Trenutno ga za vse člane univerze uporablja samo
Univerza na Primorskem. Knjižničarji in referenti posameznih vključenih
organizacij lahko uporabljajo detektor podobnih vsebin preko vmesnika v
repozitoriju.
Velika prednost naše rešitve v
primerjavi s konkurenčnimi ponudniki je velika baza slovenskih besedil, ki se
dnevno povečuje.
Vsebinsko ločimo med preverjanjem podobnosti
vsebine in preverjanjem plagiatorstva. Ustrezne programske opreme določijo
stopnjo podobnosti vsebin. O plagiatorstvu odloča človek na osnovi stopnje
podobnosti in drugih kriterijev.
Ugotavljanje podobnosti med dokumenti se v
detektorju podobnih vsebin na nacionalnem portalu odprte znanosti izvaja v dveh
korakih.
V prvem koraku, ki ga imenujemo
»ugotavljanje grobe podobnosti« (angl. fingerprinting), programska oprema za
preverjanje podobnosti določi dokumente, ki so po vsebini najbolj podobni
dokumentu, ki ga želimo preveriti. Za ta namen se uporabljajo algoritmi in
drugi procesi, ki za celotno vsebino dokumenta ali za posamezne odseke
dokumenta (poglavje, odstavek, stavek, določeno število besed) izračunajo
značilke ( Stein, 2007, Alzahrani et al., 2012, Brezovnik in Ojsteršek, 2011a).
V tem koraku program tudi določi katere dokumente bo uporabil za nadaljnjo
obdelavo.
V drugem koraku, ki ga imenujemo »ugotavljanje
fine podobnosti« (angl. pairwise feature-based exhaustive analysis), preverimo
vsak dokument z vsakim z ugotavljanjem najdaljših skupnih podnizov znakov
(Navaro, 2001).
Zaznavanje podobnosti vsebin (plagiatorstva)
se v nacionalni infrastrukturi odprtega dostopa izvaja na nacionalnem portalu.
Rezultate podobnosti lahko ob ustrezni avtentikaciji in avtorizaciji v
institucionalnem repozitoriju ali v akademskem informacijskem sistemu univerze
pogledajo pooblaščene osebe. Študent ali zaposleni na univerzi lahko vidi samo
dela, pri katerih je avtor, soavtor ali mentor. Program za preverjanje
podobnosti izvede primerjavo podobnosti za vsako delo, shranjeno v repozitorije
univerz. Program ne preverja podobnosti slik.
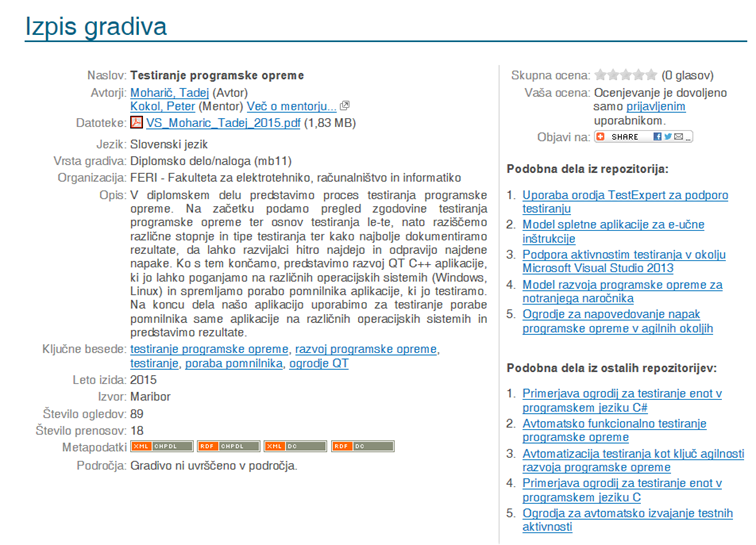
Slika 9: Primer izpisa podobnosti besedil po
primerjavi povedi med dvema besediloma (ugotavljanje grobe podobnosti)
Program, ki preverja podobnost povedi med
besedili (slika 9), odkrije podobne povedi v obeh besedilih, ki so daljše od
štiridesetih znakov.
Meja štiridesetih znakov je nastavljena na
podlagi izkušenj, ki smo jih pridobili od leta 2008 z detekcijo podobnih vsebin
na nivoju povedi. Krajše povedi običajno predstavljajo fraze ali ustaljeno
strokovno terminologijo.
Programska rešitev za
detekcijo podobnih vsebin je prilagojena analizi besedil v slovenskem jeziku (upošteva
pregibnost jezika, sinonime), kar je glavna njegova prednost v
primerjavi s konkurenčnimi produkti, ki so usmerjeni predvsem na preverjanje
besedil v angleškem jeziku. Za preverjanje besedil v slovenskem jeziku smo
razvili programsko ogrodje, ki omogoča povezovanje različnih opravil za
procesiranje besedil in tekstovno rudarjenje (npr. razčlenjevanje vsebine,
oblikoslovno označevanje, razreševanje sklicev, pomensko označevanje, delno
avtomatsko dopolnjevanje pomenskega slovarja, določanje imenskih entitet,
določanje relacij med imenskimi entitetami...). Za slovenski jezik uporabljamo
oblikoslovni slovar, ki vsebuje okrog 8.000.000 besednih oblik združenih v
okrog 320.000 lem. Kot splošni pomenski slovar smo
uporabili besedne zveze iz naslovov člankov iz slovenske, angleške in nemške
Wikipedije, ki smo jih ekstrahirali iz Dbpedije (Morsey et al., 2012) in
domensko specifični pomenski slovar, ki smo ga zgradili s pomočjo ključnih
besed, ki se pojavljajo v metapodatkih publikacij. Povedi, ki jih program za
ugotavljanje grobe podobnosti označi kot podobne, so nesporno enake v obeh
besedilih. Razlikujejo se lahko samo, če so avtorji uporabljali sinonime ali so
jih napisali v drugi osebi oziroma so v njih uporabili mašila ( npr. torej,
pa…). Program zazna podobne povedi v
besedilih, čeprav je v njih lahko zamenjan vrstni red uporabljenih besed ali so
v besedah tipkarske napake.
Algoritem za določanje podobnosti povedi med
besedili (Brezovnik in Ojsteršek, 2011a), ki smo ga dodatno nadgradili, najprej
pretvori besedilo v format UTF-8, izloči odvečne presledke in skoke v novo
vrstico (CR, LF), razbije vsebino v stavke, ki jih nato lematizira, in iz njih
izloči najbolj pogoste besede (npr. in ali, da ...) ter preostale besede iz
stavka uredi po abecedi. V tem koraku izvede tudi popravljanje tipkarskih napak
v besedah, če lahko iz oblikoslovnega slovarja ob uporabi POS označevalnika
enoumno določi za katero besedo gre.
Za popravke tipkarskih napak smo uporabili
Symmetric Delete Spelling Correction algoritem. Za lematizacijo program izvede
še normalizacijo sinonimov, ki jih imamo shranjene v pomenskem slovarju in jih
lahko brez spremembe pomena preslikamo v eno obliko.
Dober primer je normalizacija besed
»predstaviti«, »opisati«, »prikazati«, ki so v večini primerov sinonimi. Zatem
program za tako spremenjene povedi izračuna zgostitvene vrednosti (ang. hash).
Nato program primerja zgostitvene vrednosti vseh dokumentov ter za naš dokument
sestavi seznam delov besedila, ki so enaki v ostalih dokumentih.
Dokumenti, ki so med seboj podobni v povedih
za več kot 1%, so kandidati za ugotavljanje znakovne podobnosti. Če je teh
kandidatov manj kot 50, potem program vzame še ostale najbolj podobne
dokumente, ki jih dobimo po primerjavi s pomočjo algoritma BM25 (Robertson et
al., 2004).
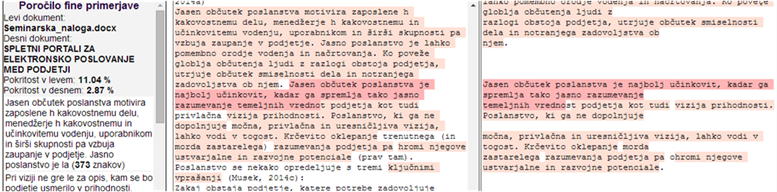
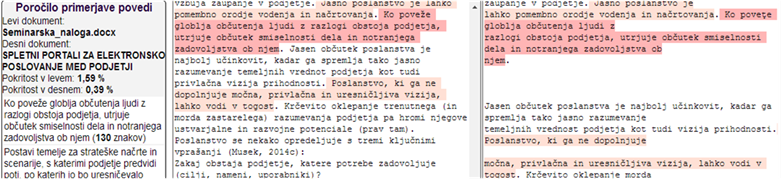
Slika 6: Primer izpisa podobnosti po izvedbi
znakovne primerjave med dvema besediloma (ugotavljanje fine podobnosti)
Program, ki izvaja znakovno primerjavo
podobnosti med besedili (slika 6), išče najdaljše skupne podnize med dvema
besediloma. Omejili smo se na skupne podnize znakov, ki so daljši od 14 znakov.
Ko dobimo najdaljše skupne podnize znakov med posameznimi dokumenti, izločimo
podnize, ki so krajši od 30 znakov in se nahajajo v istem dokumentu več kot 350
znakov od drugih skupnih podnizov znakov. Tudi zgoraj omenjene dolžine podnizov
in razdalj med podnizi smo določili na podlagi študije velikega števila
podobnih dokumentov, ki smo jih ročno pregledovali od leta 2008. Program barvno
označi besedne zveze ali dele povedi, ki so enaki v obeh dokumentih. Za
ugotavljanje skupnih podnizov obeh dokumentov smo uporabili algoritem, ki ga je
razvil Kärkkäinen s sodelavci (Kärkkäinen et al., 2009).
Pri določenih gradivih je lahko velika
razlika med izračunom podobnosti povedi in podobnosti, ki jo dobimo po znakovni
primerjavi podobnosti. To velja predvsem za gradiva, ki so si na nivoju
podobnih povedi zelo različna (npr. nobena cela poved ni enaka v obeh
dokumentih). V teh primerih so avtorji vzeli določene povedi iz drugih
dokumentov in jih delno spremenili, zato jih program za ugotavljanje podobnosti
povedi ni zaznal. Programska rešitev tudi generira skupno poročilo o podobnosti
med ocenjevanim dokumentom in izbranimi dokumenti ali med vsemi dokumenti, ki
jih je program izbral kot kandidate za izvedbo znakovne primerjave podobnosti.
Končni rezultat preverjanja podobnosti je
prikaz podobnosti dokumenta z drugimi dokumenti:
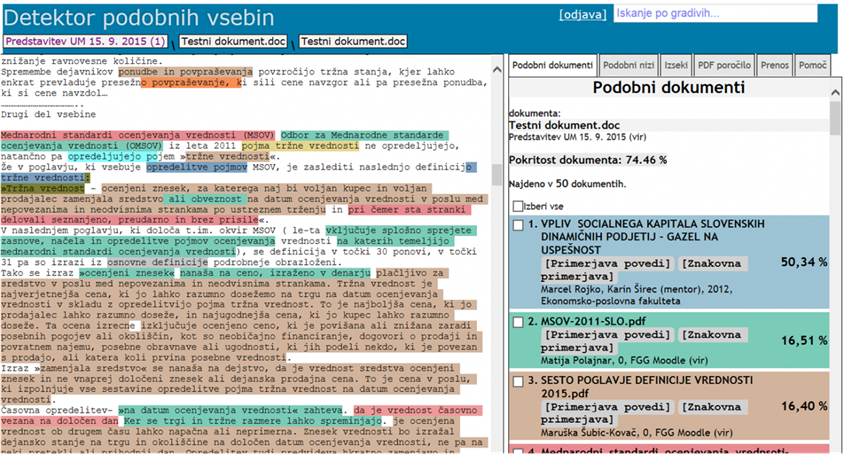
Navodila
in video navodila za uporabo sistema za detekcijo podobnih vsebin najdete na https://dpv.openscience.si/navodila/
Mobilne aplikacije
Mobilne aplikacije za iskanje
po nacionalni infrastrukturi odprtega dostopa delujejo na operacijskih sistemih
Windows Phone, Android in iOS.